Introduction à la détection automatique d’objets : les méthodes à convolution (YOLO et R-CNN) – 1re partie
Par Vincent Coulombe, 1er septembre 2023
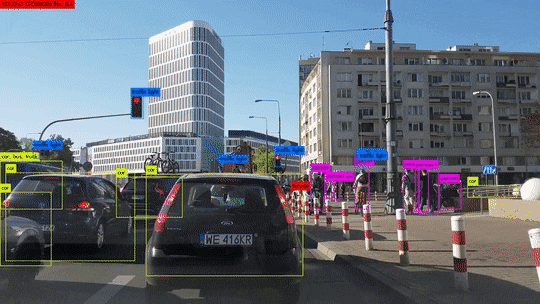
La détection d’objets est une tâche cruciale dans le domaine de la vision par ordinateur, ouvrant la voie à une multitude d’applications, allant de la sécurité à l’automatisation industrielle et à la conduite autonome. Au fil des années, différentes approches ont été développées pour relever ce défi complexe, mais deux méthodes ont émergé comme les plus populaires : « You Only Look Once » (YOLO) et « Region-based Convolutional Neural Networks » (R-CNN).
Dans cet article, nous plongerons au cœur de ces deux approches de détection d’objets pour comprendre leurs différences fondamentales et évaluer leurs performances respectives. Nous examinerons en détail pourquoi YOLO est devenu le choix privilégié pour de nombreuses applications, surpassant R-CNN en termes de vitesse et de précision. De plus, nous découvrirons comment l’algorithme de «Non-max suppression» renforce YOLO en éliminant les détections redondantes.
Cependant, l’évolution rapide de la recherche en vision par ordinateur ne s’arrête pas là. Une nouvelle famille d’algorithmes, les « Detection Transformers » (DETR), est apparue et promet de révolutionner davantage la détection d’objets. Bien que nous nous concentrions sur YOLO et R-CNN dans cet article, nous explorerons cette prometteuse famille d’algorithmes en deuxième partie, dans un article ultérieur.
Joignez-vous à moi dans cette quête pour comprendre les meilleures approches de détection d’objets et les avancées qui façonnent l’avenir de cette fascinante discipline. Sans plus attendre, plongeons dans l’univers de R-CNN et de YOLO pour déterminer quelle méthode domine actuellement la détection d’objets via convolution.
Méthodes à 2 étapes vs méthodes à 1 étape
Historiquement, deux paradigmes majeurs de détection d’objets ont émergé, chacun apportant des avancées significatives dans ce domaine passionnant. Initialement, la méthode en 2 étapes a ouvert la voie à la détection d’objets en utilisant des modèles de la famille R-CNN. Cette approche révolutionnaire a constitué une avancée majeure en découpant le processus de détection en deux phases distinctes : d’abord, la proposition de régions potentielles contenant des objets, puis la classification de ces régions. Bien que cette méthode ait été novatrice et efficace, elle souffrait néanmoins de limitations en termes de vitesse de traitement, la rendant moins adaptée aux applications nécessitant une détection en temps réel.
C’est ici que la méthode en 1 étape, représentée par les modèles de la famille YOLO, a véritablement révolutionné le domaine de la détection d’objets. Contrairement aux méthodes en 2 étapes, YOLO propose une approche intégrée, permettant de détecter les objets directement en une seule étape, d’où son nom évocateur. Cette approche a permis des gains considérables en termes de vitesse de traitement, rendant possible la détection en temps réel, ce qui s’est avéré essentiel dans de nombreux scénarios pratiques tels que la conduite autonome, la surveillance en temps réel et bien d’autres applications critiques.
Survol des modèles de la famille R-CNN
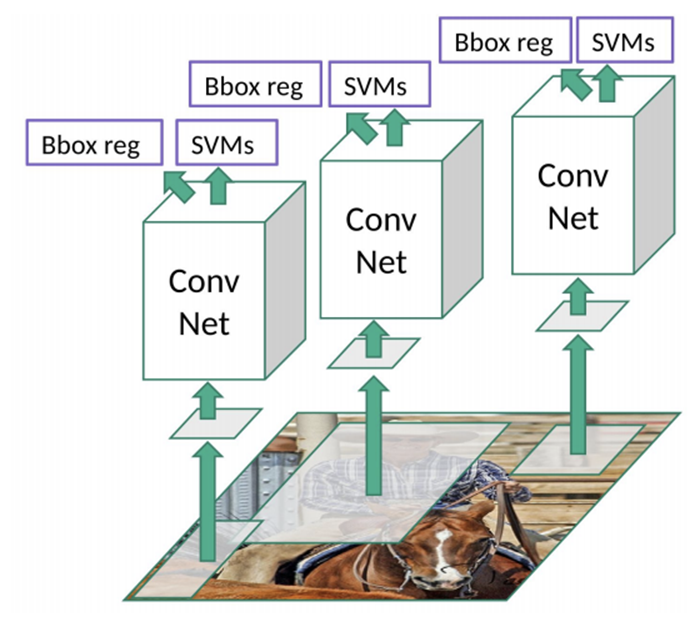
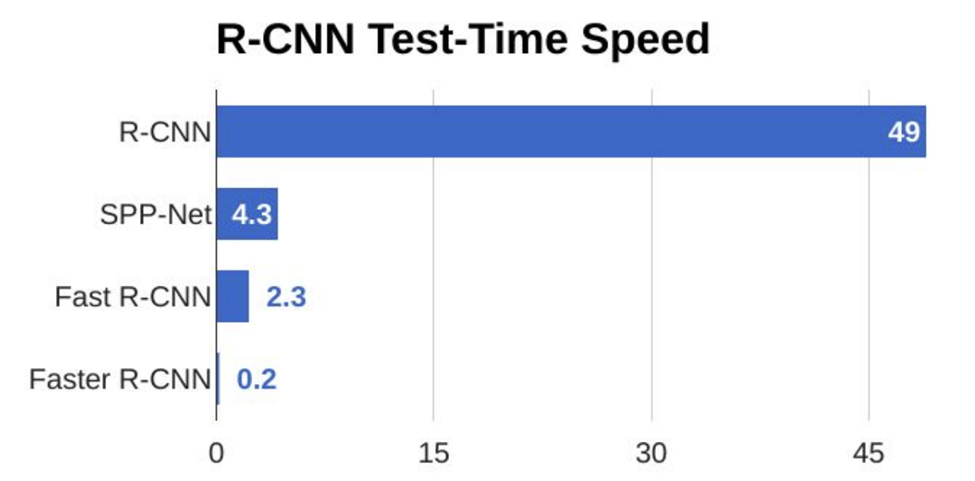
L’évolution des modèles de la famille R-CNN a été marquée par des avancées significatives dans la détection d’objets. Tout a commencé avec R-CNN, qui a introduit une approche novatrice combinant plusieurs techniques. Dans un premier temps, R-CNN utilise l’algorithme « Selective Search » pour proposer environ 2 000 régions d’intérêts potentielles dans une image. Ces régions d’intérêts sont ensuite extraites et redimensionnées pour être soumises à un réseau de neurones convolutifs (CNN) pré-entraînés afin de capturer les caractéristiques visuelles des objets présents. En parallèle, R-CNN utilise un algorithme de classification classique, tel qu’un SVM ou « Support Vector Machine », pour classifier le contenu des détections et attribuer les étiquettes appropriées aux objets. Cependant, un inconvénient majeur est que le CNN doit effectuer 2 000 inférences séparées pour une seule image, ce qui entraîne un temps de traitement d’environ 49 secondes par image. Cette durée considérable limite ainsi l’applicabilité de R-CNN dans de nombreux domaines nécessitant des réponses en temps réel.
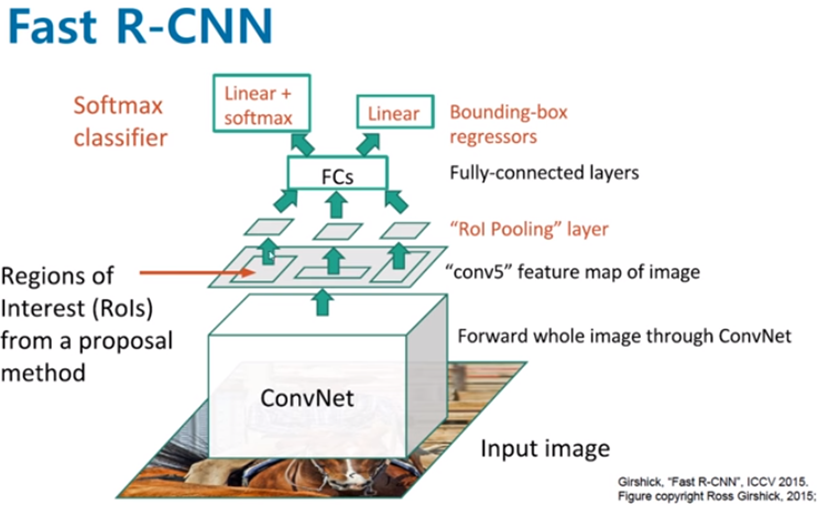
Fast R-CNN a été introduit pour surmonter les limitations de R-CNN et améliorer considérablement la vitesse de traitement de la détection d’objets. Contrairement à R-CNN, Fast R-CNN n’utilise plus un SVM pour la deuxième étape du traitement, mais il effectue désormais cette étape entièrement à l’aide d’un réseau de neurones. Cette modification a permis de simplifier et d’accélérer le processus global.
Dans Fast R-CNN, l’algorithme « Selective Search » est appliqué une seule fois sur les « feature maps » extraites directement à partir de l’image via un CNN. Les « feature maps » contiennent des informations sur les caractéristiques visuelles de l’image, ce qui permet à « Selective Search » de proposer les régions d’intérêts potentielles. Une fois que les régions d’intérêts sont identifiées, elles sont alignées avec les « feature maps » pour être redimensionnées et adaptées aux dimensions attendues par le réseau de neurones.
Le réseau de neurones prend ensuite en charge à la fois la classification des objets présents dans les régions d’intérêts et la prédiction de leurs positions. Ce processus intégré élimine les étapes redondantes de R-CNN et permet d’obtenir une détection plus rapide et plus efficace.
Grâce à cette approche, Fast R-CNN a réussi à réduire considérablement le temps de traitement par image, atteignant environ 2,3 secondes. Cependant, malgré ces améliorations significatives, le goulot d’étranglement persiste toujours en raison de l’utilisation de « Selective Search », qui prend environ 90 % du temps total de traitement. Bien que plus rapide que R-CNN, Fast R-CNN n’a pas encore atteint le niveau de traitement en temps réel souhaité dans de nombreuses applications.
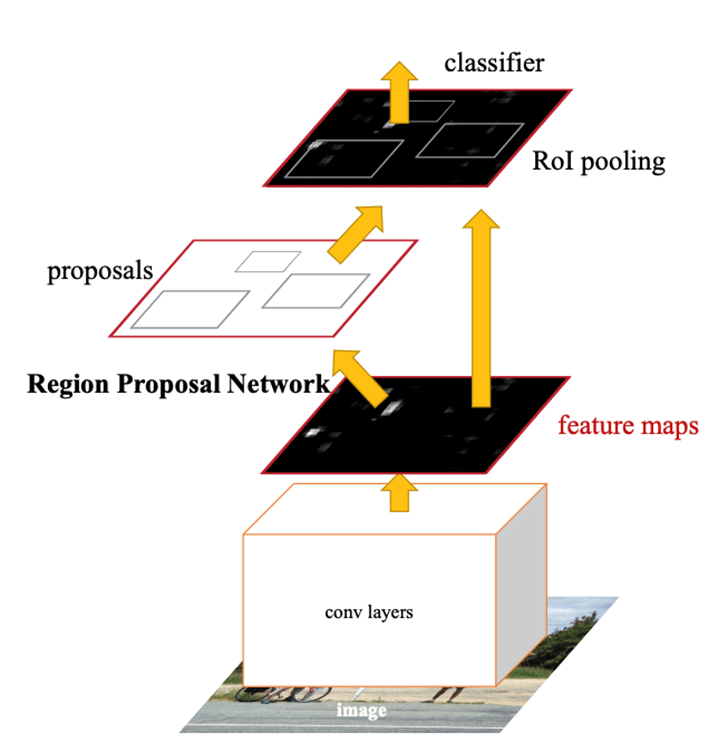
Finalement, Faster R-CNN est venu révolutionner la détection d’objets. En se débarrassant complètement de « Selective Search », Faster R-CNN a introduit un deuxième réseau de neurones CNN appelé RPN ou « Region Proposal Network » pour générer automatiquement les propositions de régions d’intérêts. Grâce à cette approche intégrée, Faster R-CNN a réussi à obtenir un temps de traitement incroyablement rapide de seulement 0,2 secondes par image, tout en maintenant un niveau de précision similaire à ses prédécesseurs.
Bien que 0,2 secondes représentent une nette amélioration par rapport aux 49 secondes initiales, nous sommes encore loin d’atteindre le traitement en temps réel (environ 0,03 secondes). Cependant, les progrès réalisés avec R-CNN, Fast R-CNN et Faster R-CNN ont définitivement ouvert la voie à la détection d’objets plus rapide et plus précise, ouvrant ainsi la porte à une multitude d’applications passionnantes dans le domaine de la vision par ordinateur.
Introduction à YOLO
YOLO est un algorithme de détection d’objets largement reconnu dans le domaine de l’apprentissage automatique. Depuis ses débuts, il a connu une dizaine de versions différentes, toutes caractérisées par leur remarquable vitesse d’exécution, réalisant des détections en temps réel. La dernière version, YOLO-NAS, est particulièrement impressionnante avec un temps de traitement d’environ 0,002 seconde par image en utilisant les cartes graphiques modernes et des tenseurs 8-bits.
Bien que les premières versions de YOLO étaient moins précises que les modèles à deux étapes, tels que ceux de la famille R-CNN, elles comprenaient une remarquable rapidité d’exécution. Au fur et à mesure des itérations, chaque nouvelle version a apporté des améliorations significatives à l’architecture du réseau de neurones, à la fonction de perte, à l’initialisation du réseau et à la taille et à la quantité de cellules de détection. Si bien que dès la version 3, YOLO a réussi à atteindre un équilibre en étant à la fois plus rapide et plus précis que R-CNN. Depuis lors, chaque nouvelle itération ne fait que creuser davantage l’écart de performance entre ces deux familles d’algorithmes.
Dans la suite de ce blog, nous allons examiner en détail le fonctionnement de la première version de YOLO. Le principe de base de cet algorithme, introduit avec YOLOv1, demeure le fondement peu modifié de toutes les versions subséquentes. Cependant, il est important de noter que chaque nouvelle version a apporté des innovations significatives qui ont permis à l’algorithme de se démarquer. Grâce à ces améliorations itératives, YOLO a réussi à atteindre des performances remarquables en termes de détection d’objets en temps réel, tout en maintenant une précision appréciable. Pour ceux qui souhaitent en savoir plus sur les innovations spécifiques apportées dans les versions subséquentes, voici les liens vers les publications de la 3e version : https://arxiv.org/abs/1804.02767, la 4e version : https://arxiv.org/abs/2004.10934, et la 7e version: https://arxiv.org/abs/2207.02696. Ces ressources vous permettront de plonger plus profondément dans les avancées qui ont permis à YOLO de continuer à évoluer et à exceller dans la détection d’objets.
Fonctionnement général de l’algorithme
L’algorithme YOLO porte bien son nom car il incarne le concept de « You Only Look Once » (On ne regarde qu’une fois) lors du traitement de l’image. Contrairement aux méthodes à deux étapes, YOLO traite l’intégralité de l’image en une seule passe pour détecter les objets. En d’autres termes, il ne décompose pas l’image en plusieurs régions d’intérêt potentiel avant de classifier ces régions.Il effectue plutôt une classification globale sur l’ensemble de l’image. Cependant, bien que YOLO traite l’image en une étape pour classifier les objets, il reste un processus de post-traitement essentiel pour raffiner les prédictions. Ce processus est appelé « Non-max Suppression » (NMS) expliqué en détail dans la section du même nom du blogue.
La théorie derrière l’algorithme
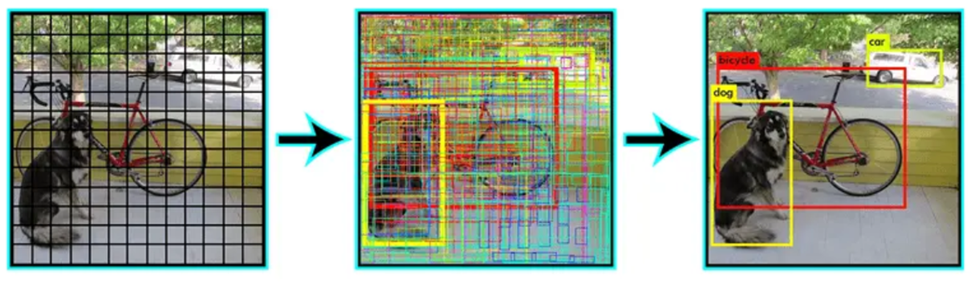
Dans cette partie théorique dédiée à YOLO, nous allons adopter une approche pratique pour expliquer le fonctionnement de l’algorithme. Pour ce faire, nous allons prendre un exemple concret et examiner comment l’algorithme traite une image donnée afin de détecter la présence du chien, du vélo et de l’automobile ci-dessous.
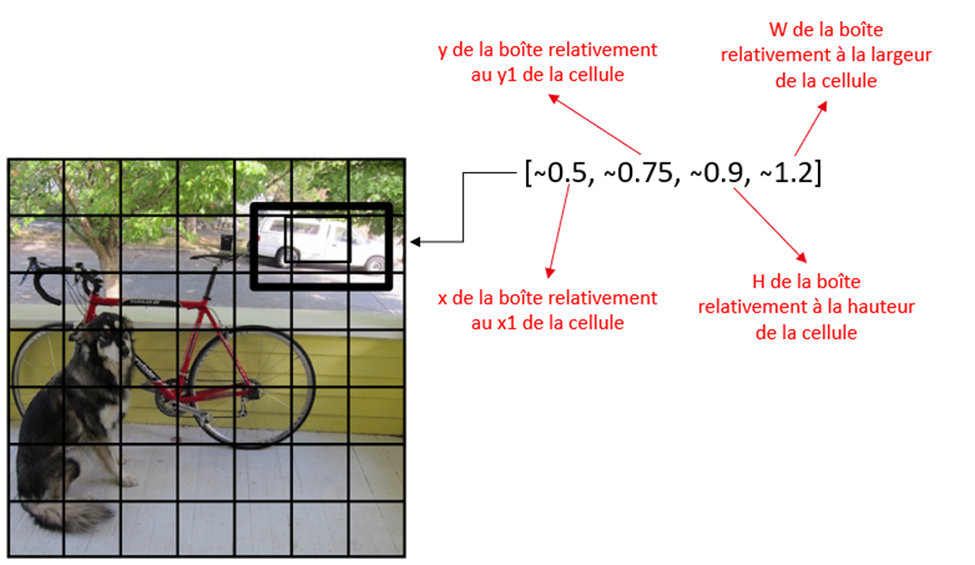
L’algorithme YOLO commence par diviser l’image d’entrée en une grille régulière de sous-sections carrées, appelées cellules, qui peuvent avoir une taille, par exemple, de 7×7.
Dans YOLO, pour détecter les objets, chaque cellule effectue plusieurs prédictions. Cependant, pour qu’un objet soit considéré présent dans une cellule, il faut que le centre de cet objet soit situé à l’intérieur de cette cellule.
Imaginons une cellule mise en évidence en rouge. Si cette cellule contient le centre d’une automobile, alors elle sera responsable de détecter cette voiture. Les autres cellules voisines, même si elles contiennent des pixels de la même automobile, ne seront pas responsables de la détecter. Seule la cellule contenant le centre de l’objet est prise en compte pour sa détection. Je comprends que ce principe puisse sembler peu intuitif, mais nous verrons dans la section « L’algorithme en pratique » comment cette vérification est réellement effectuée et pourquoi cela fonctionne.
Chaque cellule doit donc prédire un score de confiance (probabilité) qu’elle contient le centre d’un objet. De plus, elle doit prédire les coordonnées du point central de l’objet par rapport au coin supérieur gauche de la cellule (x1, y1), généralement représentées par (x, y). La cellule doit également prédire la largeur (w) et la hauteur (h) de l’objet par rapport aux dimensions de la cellule, ce qui donne la taille et la forme de l’objet détecté.
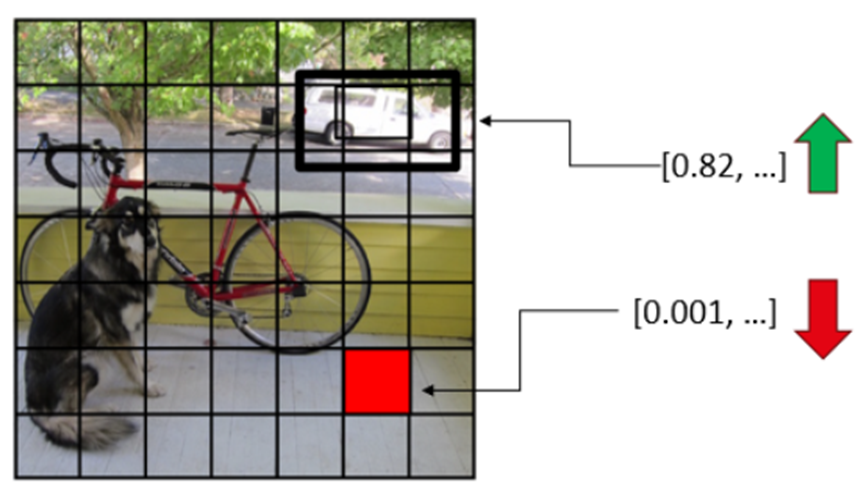
Lors de l’entraînement, l’objectif est de pousser l’algorithme à prédire correctement les valeurs (x, y, w, h) de l’objet ainsi que le niveau de confiance des cellules contenant le point central d’un objet. De même, on tente de réduire le niveau de confiance des cellules qui ne contiennent pas d’objets.
Enfin, chaque cellule doit également prédire la classe (par exemple, chien, chat, voiture, etc.) de l’objet qu’elle est la plus susceptible de contenir, qu’elle en contienne effectivement un ou non.
Chaque cellule effectue donc plusieurs prédictions (probabilité de contenir un objet, emplacement potentiel de l’objet et classe de l’objet). L’algorithme produit ainsi 7 x 7 = 49 détections potentielles. Le résultat peut ressembler à celui illustré dans la figure ci-dessous. Il est donc nécessaire d’utiliser une petite heuristique pour filtrer les fausses détections. Cette heuristique s’appelle «Non-max Suppression» et est expliquée en détail dans la section du même nom.
L’algorithme en pratique
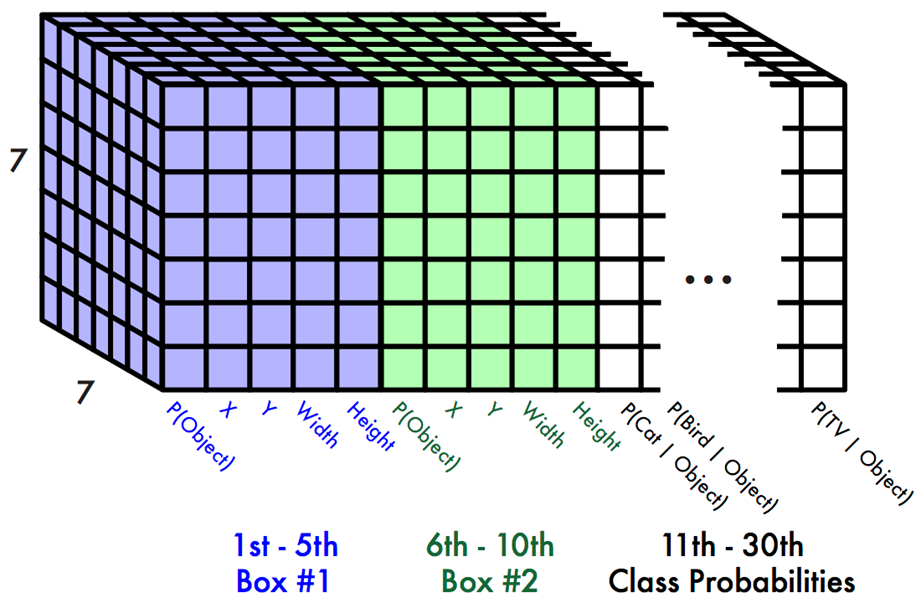
En pratique, l’approche YOLOv1 repose principalement sur la manipulation du tenseur de sortie et la fonction de perte. Le tenseur de sortie a une dimension de 7 x 7 x 30 = 1 470, ce qui signifie qu’il y a 30 valeurs de sortie pour chacune des 49 cellules de l’image. Mais pourquoi 30 sorties?
– Les 5 premières sorties correspondent à la probabilité que la cellule contienne le centre d’un objet, suivies des coordonnées positionnelles de l’objet (x, y, w, h).
– Les 5 sorties suivantes représentent une deuxième chance pour la cellule de prédire correctement si elle contient ou non un objet, ainsi que ses coordonnées. Cette redondance dans les prédictions permet d’améliorer la détection, car les mauvaises détections seront filtrées ultérieurement par la « Non-max Suppression ».
– Les 20 sorties restantes indiquent les probabilités pour chaque classe possible de l’objet dont le centre est contenu dans la cellule. Étant donné que YOLOv1 a été entraîné sur un jeu de données contenant 20 classes (PascalVOC), il y a donc 20 probabilités. En phase d’inférence, seule la classe avec la probabilité la plus élevée est prise en compte.
Cependant, cette méthode présente plusieurs faiblesses. Par exemple, le nombre maximal de détections possibles est limité à 49, toutes les cellules ont la même taille, l’entraînement à partir de valeurs aléatoires est long et fastidieux, et la raison pour donner 2 chances à chaque cellule n’est pas explicitée. Ces limitations ont été corrigées dans les versions ultérieures de l’algorithme YOLO, grâce à certaines des innovations annoncées en introduction.
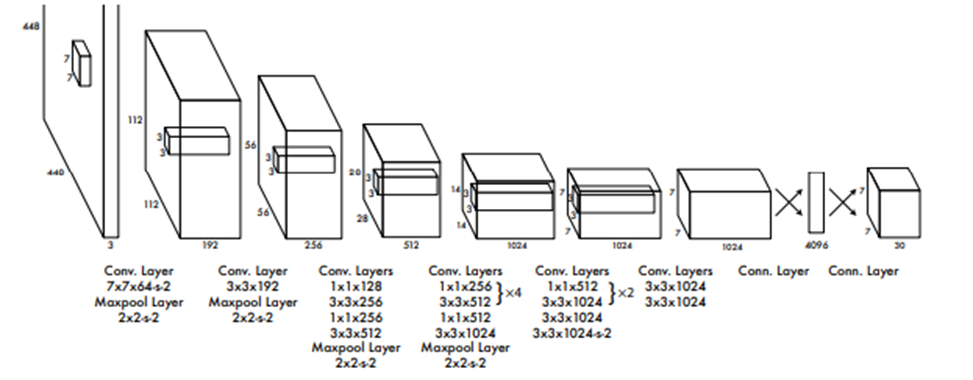
Voici une présentation de l’architecture globale de l’algorithme YOLOv1. Son but est de mettre en évidence la position du tenseur de 1 470, reformaté en 7 x 7 x 30, qui se trouve à la fin de cette architecture. Cependant, il est important de noter que cette architecture en elle-même n’est pas innovante. Il s’agit simplement d’un réseau de neurones à convolution fortement inspiré des modèles de la famille ResNet. Il est intéressant de mentionner que la plupart des versions ultérieures de YOLO introduisent leurs propres architectures, toutes basées sur des CNN (réseaux de neurones à convolution) au moment où ces lignes sont écrites.
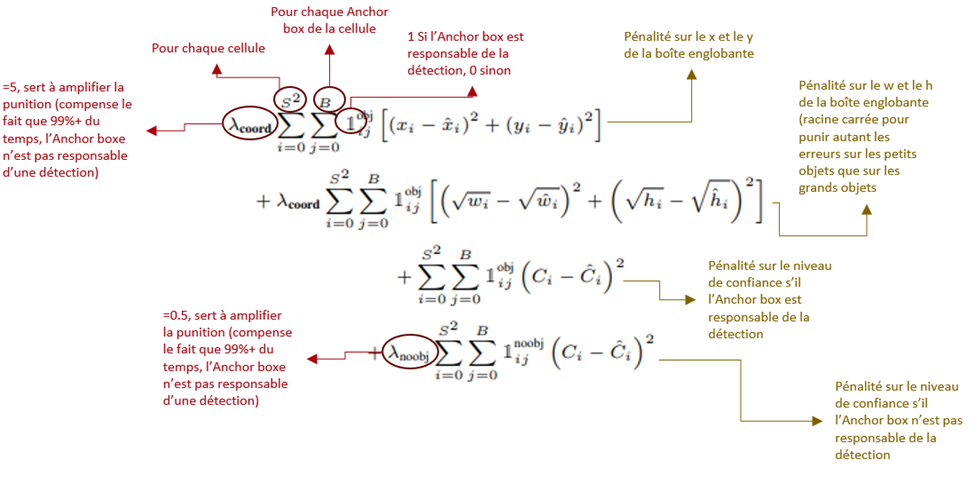
La fonction de perte de la première version de YOLO est complexe et peut être intimidante, même pour les connaisseurs, car elle ne comporte pas les métriques usuelles comme celles liées au IoU (introduites dans la version 4) ni l’entropie croisée (introduite dans la version 3). Ici, le problème est plutôt considéré comme un ensemble de régressions. La fonction de perte reflète bien cette approche. Elle correspond à l’addition de cinq équations, chacune responsable d’une partie du comportement final de l’algorithme :
– La première équation pénalise quadratiquement les erreurs sur les coordonnées x et y des cellules contenant le centre d’un objet.
– La deuxième équation pénalise linéairement les erreurs sur les dimensions w et h des cellules contenant le centre d’un objet.
– La troisième équation renforce le niveau de confiance des cellules contenant le centre d’un objet.
– La quatrième équation diminue le niveau de confiance des cellules ne contenant pas le centre d’un objet.
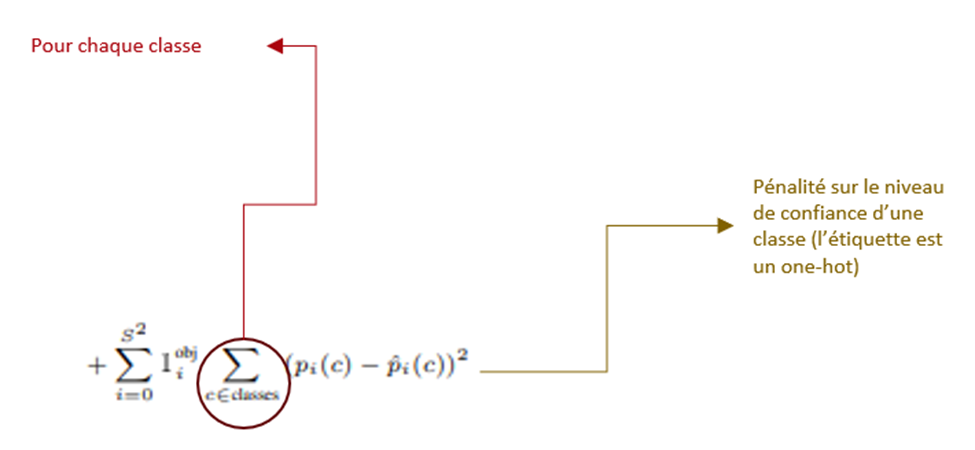
– La cinquième équation représente la perte pour la classification, traitée également comme une régression, où l’étiquette est un vecteur « one-hot ».
Il est important de noter que l’entraînement doit se faire dans un contexte supervisé, où chaque image est associée à une étiquette. Cette étiquette doit contenir toutes les informations nécessaires pour calculer la fonction de perte, indiquant quelle cellule est responsable de quel objet, ainsi que la position et la forme de chaque objet par rapport à cette cellule spécifique. L’étiquette doit également contenir, sous forme d’un vecteur « one-hot », la classe à laquelle chaque objet appartient.
Le «Non-max Suppression» (NMS)
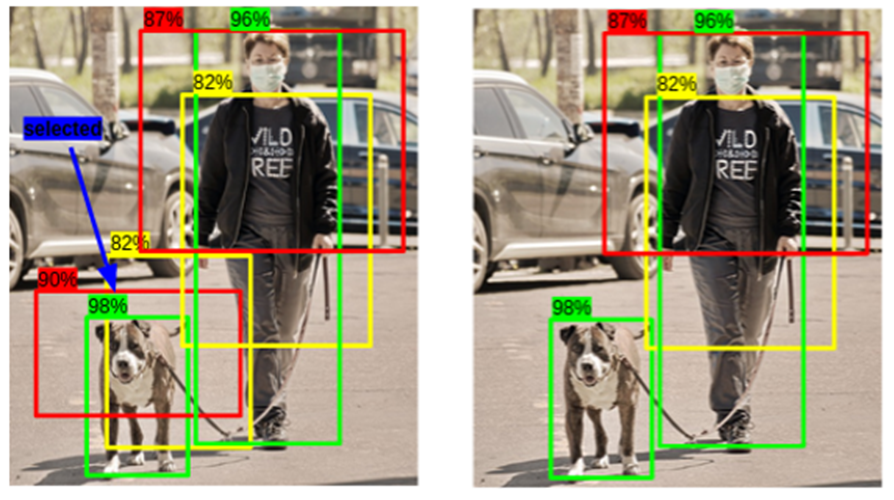
Après avoir parcouru la section précédente, vous comprendrez que l’utilisation de l’algorithme de « Non-max Suppression » est essentielle au bon fonctionnement de YOLO. En effet, ce modèle de réseau de neurones produit un tenseur 7 x 7 x 30 qui contient plusieurs informations pour chaque cellule de l’image. Ces informations incluent le niveau de confiance quant à la présence d’un objet au centre de la cellule, ainsi que la position, la forme et la classe de cet objet.
Il est important de noter que même les cellules qui ne contiennent aucun objet vont tout de même générer des valeurs pour ces informations. Cependant, ces valeurs pourraient correspondre, dans le cas d’un modèle bien entrainé, à un faible niveau de confiance ainsi qu’à la position et la classe d’un objet à proximité. Il devient donc nécessaire de filtrer ces détections redondantes pour ne conserver que les détections pertinentes.
Ce filtrage s’effectue via l’algorithme de Non-max Suppression. Cet algorithme se déroule en plusieurs étapes :
Éliminer les détections avec un niveau de confiance < 0,6 (ou tout autre chiffre entre 0 et 1, à choisir)
Sélectionner la détection avec le plus haut niveau de confiance
Éliminer toutes les détections de la même classe qui chevauchent la détection en 2
Répéter 2 et 3 jusqu’à ce qu’il n’y ait plus de chevauchement entre les détections d’une même classe
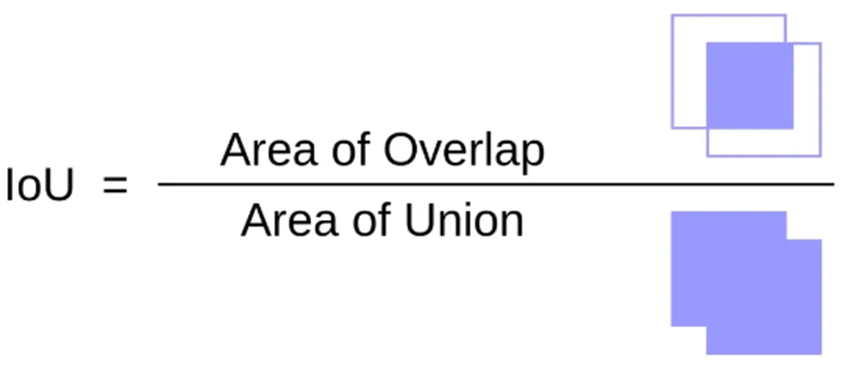
Dans ce contexte, le chevauchement est défini par un indice d’intersection sur union (IoU) supérieur à 0,5 (IoU > 0,5). Ce chiffre peut varier en fonction du problème à résoudre. Par exemple, si le modèle est utilisé pour détecter chaque grain dans un épi de maïs, il faudra probablement utiliser un IoU plus petit que 0,5 comme critère de chevauchement. Cela évitera que l’algorithme élimine de vraies détections en les considérant comme des détections redondantes.
Conclusion
En conclusion, nous avons passé en revue deux approches populaires pour la détection d’objets : R-CNN et YOLO. En comparant ces méthodes, nous avons découvert que YOLO se démarque par sa rapidité et sa précision supérieure, ce qui en fait le choix privilégié pour les applications de détection d’objets en temps réel.
L’algorithme de «Non-max suppression» joue un rôle crucial dans l’efficacité de YOLO, éliminant les détections redondantes et ne conservant que les prédictions les plus pertinentes. Cette fonctionnalité a grandement contribué à son succès en pratique.
Alors que je me suis concentré sur YOLO dans cet article, il est important de noter que le domaine de la détection d’objets est en constante évolution. De nouvelles approches et algorithmes émergent régulièrement pour relever les défis de manière innovante.
Dans le futur, il sera passionnant de continuer à explorer les développements récents et les tendances émergentes en matière de détection d’objets. Une de ces approches prometteuses est la famille d’algorithmes appelée «Detection Transformers» (DETR), que nous pourrons aborder dans de prochains articles afin de mieux comprendre leur fonctionnement, leurs avantages et leurs limites.
La recherche et l’innovation dans le domaine de la détection d’objets continueront de jouer un rôle essentiel pour améliorer les performances et l’efficacité des systèmes de détection. Restez à l’affût pour de futures publications, où nous continuerons à explorer les nouvelles avancées et les innovations passionnantes dans le domaine, y compris les derniers développements autour des Detection Transformers (DETR).
Nous avons à cœur de protéger vos données. Nous utilisons des cookies pour vous offrir une meilleure expérience numérique. En acceptant, vous consentez à notre utilisation de ces cookies.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.