Décrypter le NLP (1re partie) : regex, bag-of-words, lemming, stemming et word embedding
Par Vincent Coulombe, 30 novembre 2022
Du « regex » au « word embedding » en passant par le « stemming », le « lemming » et les « bag-of-words », le traitement de la langue naturelle (Natural Language Processing ou NLP en anglais) s’avère être un terreau fertile pour les concepts et techniques aux noms plus mystérieux les uns que les autres. C’est pourquoi je vous propose ce mois-ci, un blogue à saveur plus technique qui permettra de démystifier ces termes techniques.
Ah la langue! Cette belle invention qui nous permet d’affirmer, d’expliquer, d’exprimer… Bref, de communiquer. Il n’y a pas à dire, nous ne serions pas où nous sommes aujourd’hui sans elle! Et je trouve que nous avons la fâcheuse tendance à la prendre pour acquise!
Une tendance qui, malheureusement, se pulvérise aussi vite que le Titanic sur un iceberg lorsque vient le temps d’essayer de faire comprendre notre langage à un ordinateur. C’est dans ces moments-là, en plein milieu d’une perte de son latin, qu’il est possible de prendre pleinement conscience de la fabuleuse richesse de la langue naturelle.
Richesse que, depuis la 2e guerre mondiale, les scientifiques essayent de numériser. Ce sont des décennies d’avancées qui ont permis à des entreprises comme IBM, Google et Amazon de créer les premiers modèles de traduction, moteurs de recherche et algorithmes de recommandation suffisamment puissants pour être commercialisés.
Le tout, d’abord grâce à des modèles à base de règles, puis des modèles génératifs (statistiques) et des modèles discriminatifs (Machine Learning). Pour finalement en venir à utiliser le Deep Learning.
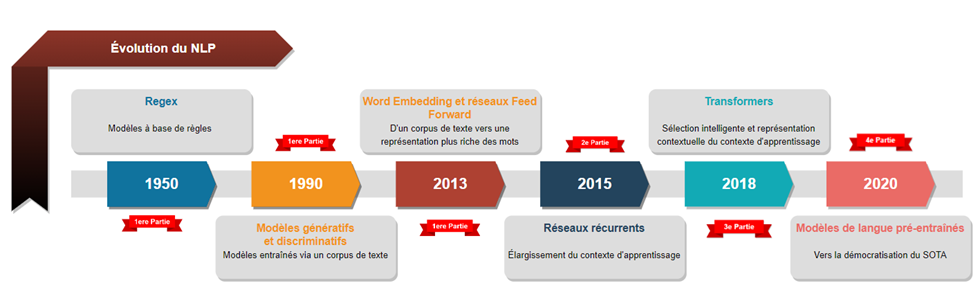
Comme dans bien des domaines, la complexification des techniques est inévitable, car chaque nouveau modèle vient pallier certaines lacunes du précédent. Ce qui, j’en conviens, en fait beaucoup à avaler. C’est pourquoi je vous propose de manger l’éléphant une bouchée à la fois en vous présentant dans cette première partie seulement les techniques qui ont précédé les réseaux récurrents. Soit celles qui sont apparues entre 1950 et 2013.
Le regex
Première technique que nous allons voir, le regex est l’abréviation du terme « expression régulière » (regular expression). Cette technique a été inventée dès les années 1950 par Stephen Cole Kleene afin d’être en mesure de créer un outil de recherche de pattern dans n’importe quel texte! Bref, il s’agit d’une espèce de langage universel qui permet aux informaticiens d’analyser et de manipuler n’importe quel texte.
Par exemple, en regex, le symbole « \s » signifie un espace blanc dans un texte. Il est donc possible (quoique peu utile) d’aller chercher les espaces blancs d’un texte avec cette expression :
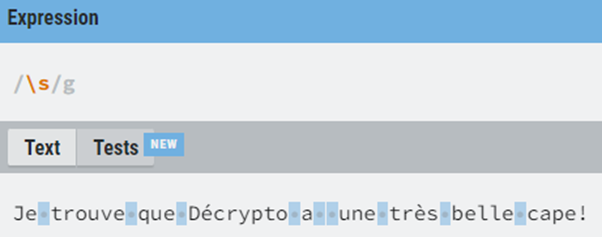
Figure 2 : exemple de match regex pour \s. L’outil utilisé est disponible ici : https://regexr.com/
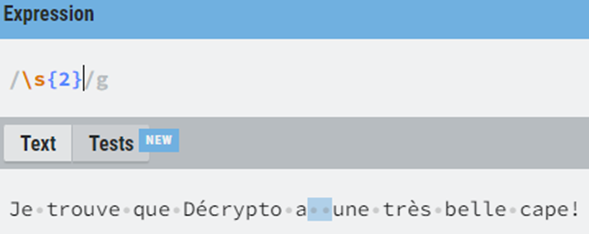
On peut aussi préciser qu’on cherche seulement les doubles espaces en ajoutant « {2} » à notre regex. Ainsi, il est possible d’isoler les instances de notre texte où on aurait malencontreusement ajouté un espace supplémentaire entre nos mots. Ce qui pourrait nous permettre de venir supprimer ces espaces superflus.
Ceci n’est qu’un exemple d’utilisation du regex. Il est aussi possible d’en écrire des plus complexes et même d’en combiner dans des programmes informatiques afin d’être en mesure d’isoler l’adresse courriel d’un texte, d’aller chercher les ingrédients d’une recette ou bien de trouver les noms propres dans un document.
Le regex s’avère donc être au programmeur NLP ce que le marteau est au travailleur de la construction. Très rarement l’outil optimal pour la tâche, celui-ci est souvent préféré à des techniques plus complexes pour des tâches simples, étant donné sa rapidité et sa polyvalence.
De plus, tel qu’il est possible de voir à la Figure 1, il fût un temps où les meilleurs modèles de traitement de la langue (je parle de traduction automatique, d’extraction d’information, de chatbot, etc.) n’étaient que des combinaisons ultra-complexes de regex qui permettaient d’avoir une modélisation honnête, quoique non optimale, d’une langue donnée.
Mais pourquoi non optimale me direz-vous? Eh bien disons que ces modèles à base de règles avaient tendance à avoir un niveau de précision correct, mais un très mauvais taux de rappel (si ces termes ne vous disent rien, je vous invite à aller lire mon blogue sur la classification.
Ces lacunes ont permis à d’autres modèles de briller sur la scène NLP.
Les modèles génératifs et discriminatifs
Pourquoi se casser le bicycle à programmer toutes les règles syntaxiques et sémantiques d’une langue alors qu’on n’a qu’à montrer à un algorithme un tas d’exemples et de lui laisser la tâche d’apprendre ces mêmes règles?
C’est exactement le raisonnement derrière les premiers modèles génératifs. Ceux-ci étaient utilisés pour faire de la classification de textes (analyse de sentiment, détection de langue, etc.) en calculant les probabilités d’occurrences de certains mots en fonction des autres mots du texte. En ce sens, la plupart de ces modèles reposaient sur la règle de Bayes (un concept dont nous ne traiterons pas dans cet article).
Selon le même ordre d’idée, les modèles discriminatifs font aussi de la classification de textes, mais au lieu d’apprendre les règles syntaxiques et sémantiques d’une langue via des statistiques, ils se concentrent à apprendre à différencier et discriminer des mots ou des groupes de mots grammaticalement ou sémantiquement différents. Et comme il est souvent plus facile de détruire que de construire, les modèles discriminatifs ont tendance à avoir de meilleures performances pour les tâches de classification de textes comparativement aux modèles génératifs.
Le bag-of-words
Bon, une fois que nos modèles génératifs et/ou discriminatifs sont prêts, il suffit de leur donner du texte pour les entraîner (calculer les probabilités ou optimiser la discrimination entre les classes). Mais comment? Eh bien la méthode retenue est celle du « bag-of-words » qui n’est qu’un gros vecteur de la même longueur que tous les mots uniques de mon corpus d’entrainement et qui contient le nombre d’occurrences de ceux-ci. La 4 illustre bien le principe de création d’un « bag-of-words ».
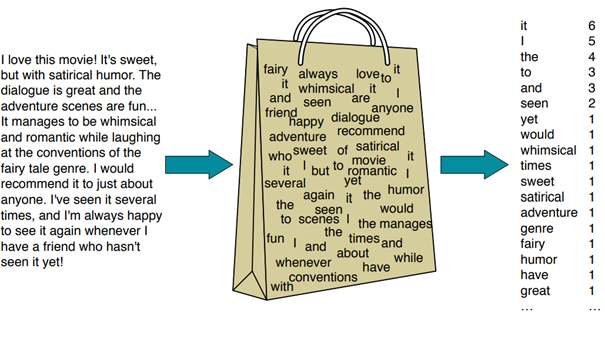
Le problème avec le « bag-of-words », c’est qu’il est très grand (de la même longueur que le vocabulaire du corpus de texte). Et donc, puisqu’il n’arrivera jamais qu’on ait à traiter un texte contenant tous les mots de notre vocabulaire, celui-ci sera possiblement rempli à plus de 99 % de zéros. Par exemple, si j’ai la phrase :
Le chien et le chat se chicanent.
Eh bien le « bag-of-words » aura un 2 à la position correspondant à « le » et un 1 aux positions correspondantes aux autres mots. Tel qu’illustré à la 5.

Ce « bag-of-words » contient alors un grand total de six positions (le, chien, et, chat, se, chicanent) plus grandes que zéro. Alors, si notre vocabulaire est de 25 000 mots, 24 994 positions seront zéro. Ce qui est évidemment un contexte d’apprentissage très difficile pour n’importe quel modèle. Il a donc fallu trouver une manière de rapetisser la taille des « bag-of-words » sans que ceux-ci ne perdent leur capacité à représenter tout notre vocabulaire.
La normalisation
C’est exactement le problème que tente de régler la normalisation. En effet, celle-ci permet de diminuer la taille du « bag-of-words » tout en gardant tous les mots pertinents dans celui-ci. Mais comment? Eh bien, il existe des tonnes de méthodes, mais les trois plus populaires sont les suivantes :
- Retrait des « stop words » : retirer les mots à faible valeur sémantique (la, le, à, de, des, etc.) du vocabulaire. Le tout implique évidemment de poser l’hypothèse que ces mots n’auront pas ou peu d’impact sur la qualité de notre analyse (ce qui est souvent le cas).
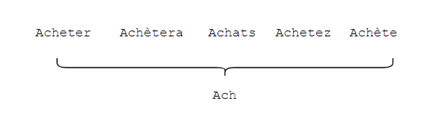
- Réduire les mots à leurs racines (ou stemming) : réduire tous les mots ayant la même racine lexicale. Tel qu’illustré à la figure 6.
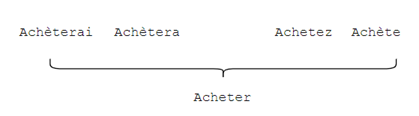
Réduire les mots à leurs lemmes (ou lemmatisation) : moins utilisée que le « stemming » puisqu’elle est plus couteuse en calcul, la lemmatisation permet de réduire les mots à leur lemme, soit leur unité sémantique la plus courte. À noter que, contrairement à la racine, le lemme est toujours un mot compris dans le dictionnaire. La figure 7 illustre ce propos.
Donc, supposons que notre « bag-of-words » passe de 25 000 mots à 6 500 mots après normalisation, on vient de diminuer pas mal le nombre de zéros dans celui-ci! Toutefois, cette méthode comporte encore plusieurs lacunes qui ne lui permettent pas d’obtenir des résultats comparables aux modèles d’aujourd’hui. Notamment, le fait que le « bag-of-words » ne donne que le nombre d’occurrences des mots et non leur position relative dans la phrase. Cela veut dire que les deux phrases suivantes :
- J’aime décrypto, mais pas sa cape.
- J’aime sa cape, mais pas décrypto.
auraient exactement le même « bag-of-words » et donc il serait impossible pour un modèle utilisant cette technique de les différencier. De plus, la seule information qu’on a sur les mots de notre texte est leur occurrence. Ce qui est mieux que rien, mais il serait intéressant de pouvoir travailler avec une représentation plus riche de ceux-ci. Ce qui nous amène au « word embedding ».
Le word embedding
Disons que nous avons un « bag-of-words » représentant un texte composé d’un seul mot, soit « chien ». Alors notre « bag-of-words » serait rempli de zéros, à l’exception d’un 1 à la position du mot chien (8) :
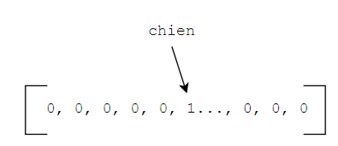
Ce qui, on s’entend, est une représentation excessivement mauvaise du mot chien. Une meilleure représentation serait, par exemple, de donner des scores entre 0 et 1 aux autres mots de notre « bag-of-words » à savoir si ce mot est plus ou moins proche de chien. Par exemple japper, étant proche de chien, pourrait être à 0.9 alors que hockey pourrait être à 0.1. On obtient alors la représentation, un peu, plus riche du mot chien (9) :
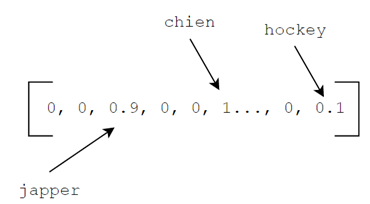
Suivant cette logique, il pourrait être intéressant de ne plus avoir de zéros dans notre vecteur, mais bien uniquement des chiffres entre 0 et 1 en fonction de leur proximité avec le mot chien. Eh bien, cette représentation existe! Elle s’appelle « l’embedding » du mot chien.
Les « word embeddings » de notre vocabulaire ne sont donc rien de plus qu’une collection de vecteurs (un par mot) de chiffres entre 0 et 1.
Permettant d’avoir une représentation sémantique extrêmement riche des mots, ceux-ci ont créé, en combinaison avec l’arrivée du « Deep learning », une petite révolution à l’époque (on parle de 2013-2014) en obtenant des résultats vraiment meilleurs que les approches précédentes.
Bon, je pourrais élaborer sur le sujet et parler des techniques d’entrainement (CBOW, Skip-gram) ainsi que des types de « word embedding » (Word2vec, Glove, FastText, etc.), mais je crois que cet article est déjà assez long comme ça. Je vous laisse donc vous renseigner sur ces magnifiques techniques!
Vers la 2e partie
Bon, c’est bien beau le « word embedding » et c’est clairement la technique la plus puissante que je vous ai exposée aujourd’hui, mais ce n’est pas parfait! Notamment, leur grande taille les rend très couteux à utiliser! Imaginez devoir analyser un document de 100 mots avec des « embeddings » de 300… Ça ferait un vecteur d’entrée de taille 30 000 qui nous ramènerait alors au même problème qu’avec le « bag-of-words ». C’est pourquoi, en pratique, on passe aux modèles la somme des « embeddings » du texte. Ce qui crée un nouveau problème! Maintenant, on a une représentation sémantique intéressante de celui-ci, mais on perd toute information sur la position des mots qu’il contient.
On en revient alors au même problème que précédemment : les deux phrases suivantes ont le même vecteur d’entrée dans notre modèle.
- J’aime décrypto, mais pas sa cape.
- J’aime sa cape, mais pas décrypto.
Heureusement, nous avons trouvé une solution : les réseaux de neurones récurrents. Ceux-ci seront présentés dans notre prochain article de blogue. Stay tuned!